
A project on Data analytics involves several steps:
- Understanding problem statement
- defining the objectives of a project
- gathering necessary data
- processing the raw data into clean data
- generating visualization, summary statistics, finding data outliers
- identifying suitable data mining methods and choosing between them
- analyzing and evaluating the results
- communicating the results
How can we perform all these actions in organised way? While executing the data analysis projects in companies, there is possibility to approach data-mining haphazardly, create many parallel processes across departments and duplicate the efforts.
Thus, a methodology for planning and executing projects in analytics is clearly required, which is industry-neutral, tool-neutral and application-neutral. In this article, a brief history of methodologies for data analytics is presented first. Afterwards, two different methodologies are described:
- KDD (Knowledge Discovery in Database) methodology
- CRISP-DM (Cross-Industry Standard Process for Data Mining) methodology
History of methodologies for data analysis
Machine learning, knowledge discovery from data and related areas experienced strong development in the 1990s. Both in academia and industry, the research on these topics was advancing quickly. Naturally, methodologies for projects in these areas, now referred to as data analytics, become a necessity. In the mid‐1990s, both in academia and industry, different methodologies were presented.
The KDD methodology was formulated by Usama Fayyad, Gregory Piatesky-Shapiro and Pandhraic Smyth in 1996. Gregory Piatesky-Shapiro coined the term KDD – “Knowledge discovery in databases”.
“The term “data mining” is used most by statisticians, database researchers, and more recently by the MIS and business communities. Here we use the term “KDD” to refer to the overall process of discovering useful knowledge from data. Data mining is a particular step in this process—application of specific algorithms for extracting patterns (models) from data. The additional steps in the KDD process, such as data preparation, data selection, data cleaning, incorporation of appropriate prior knowledge, and proper interpretation of the results of mining ensure that useful knowledge is derived from the data”
Page 28, Communication of the ACM, 1996
Another methodology that is most successful in the industry is CRISP-DM methodology. Conceived in 1996, this project had five partners from industry – SPSS, Teradata, Daimler AG, NCR Corporation and OHRA, an insurance company. In 1999, first version was presented.
“CRISP-DM has not been built in a theoretical, academic manner working from technical principles, nor did elite committees of gurus create it behind closed doors. Both these approaches to developing methodologies have been tried in the past, but have seldom led to practical, successful and widely–adopted standards. CRISP-DM succeeds because it is soundly based on the practical, real-world experience of how people do data mining projects.”
Page 4, CRISP-DM 1.0, Step by step data mining guide
The KDD Process
KDD process proposes a sequence of nine steps necessary to extract knowledge from data. The KDD process is interactive and iterative. The overview of steps constituting the KDD process is as below:
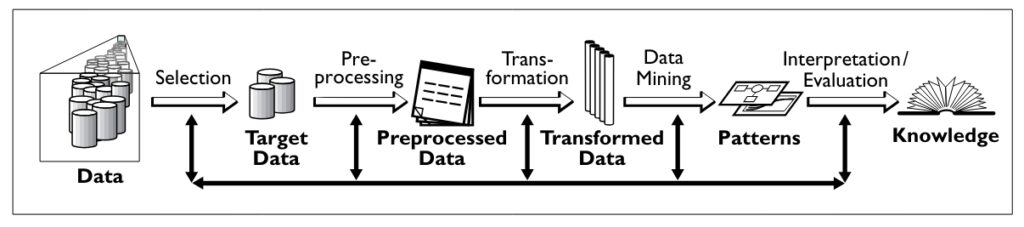
The nine steps are:
- Learning the application domain: What is expected in terms of application domain? What are the characteristics of the problem? For e.g if you are working for a Bank, understanding common behavior patterns of loan defaulters will help in building robust loan default prediction model.
- Creating a target data-set: What data are needed for the problem? Which attributes? This is where application domain comes into play. Once the application domain is known, the data analyst team should be able to identify the data necessary to accomplish the project. What data attributes can you think of for creating load default prediction model?
- Data cleaning and preprocessing: How should missing values or outliers should be handled? Are there any new attributes to be created from exiting attributes? Is it necessary to put the data in specific format, such as tabular format.
- Data reduction and projection: Irrelevant attributes should be removed. Which features should we include to analyse the data? From available features which one should be discarded?
- Choosing the data mining function: Which type of methods should we use? Four types of methods are: summarisation, classification, clustering and regression.
- Choosing data mining algorithm: Given the characteristics of the problem and characteristics of the data, which method should be used.? For e.g. models for categorical data are different from models for numeric data.
- Data mining: searching for the patterns in the data using classification, regression or clustering methods to name a few. The choice of method depends on many different factors: ability to handle missing values, capacity to deal with outliers, computational efficiency etc.
- Interpretation: interpreting the discovered patterns. Selecting the useful patterns for a given application domain is the goal of this step. It is common to go back to previous steps when results are not as good as expected.
- Using discovered knowledge: How can we apply new knowledge in practice? This step involves integration of new knowledge into the operational system.
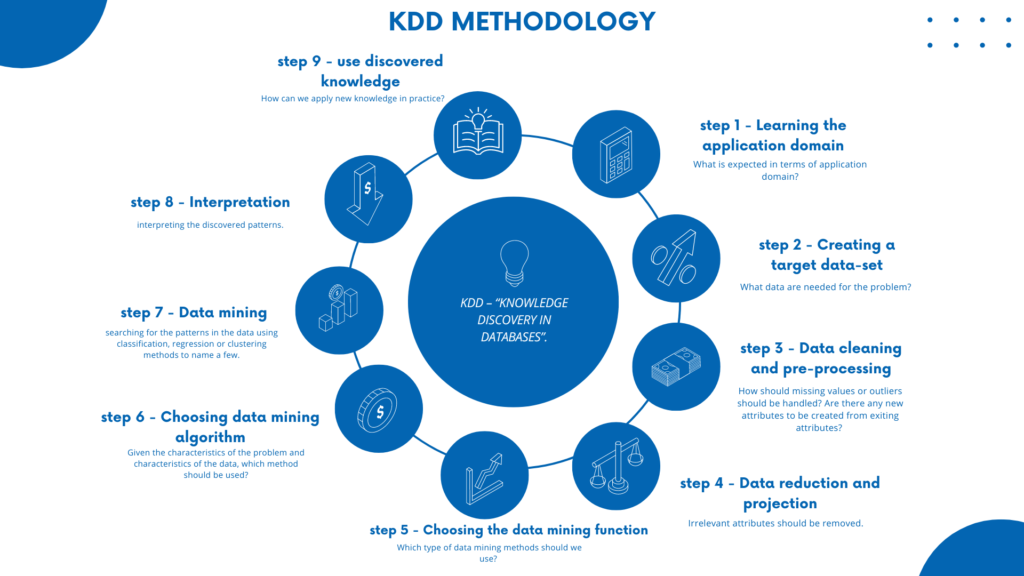
Though nine steps are described sequentially, in practice they are performed iteratively. For e.g. some methods are able to deal with missing values, others not. This requires to re look at step number 6 – choosing data mining algorithm.
The CRISP-DM Methodology
According to CRISP-DM, a given data mining project has a life cycle consisting six phases. The phase sequence is adaptive. That is, the next phase in the sequence often depends on the outcome associated with the previous phase. For e.g. if we are into modeling phase, depending upon the characteristics of model, we may have to return to the data preperation phase for further refinement.
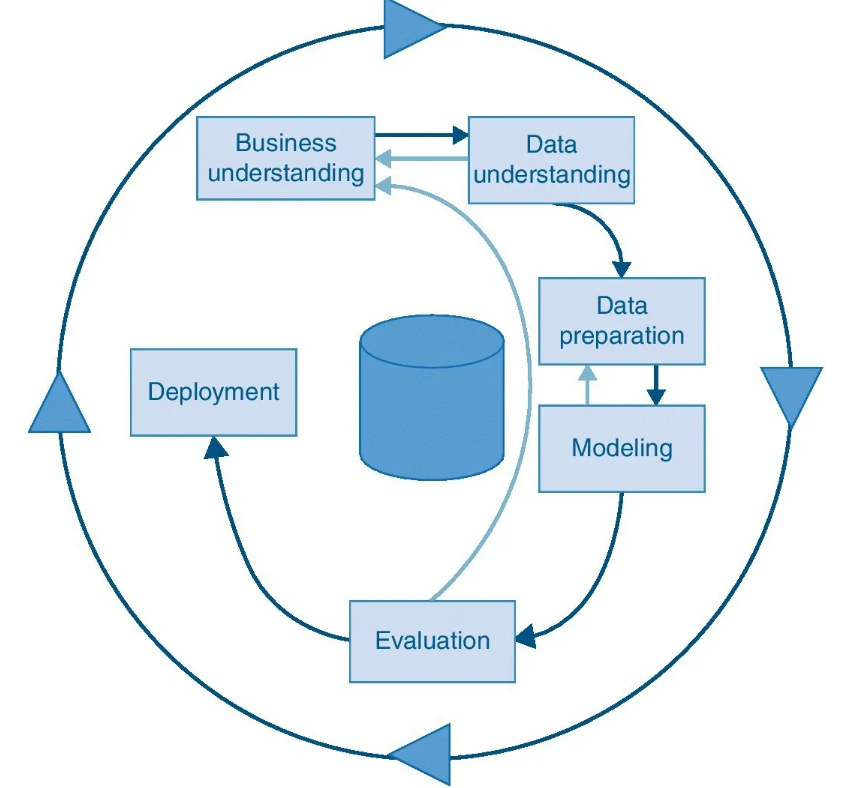
The iterative nature of CRISP is shown by the outer circle. The dependencies between the phases are shown by arrows. Here is a outline for each phase:
- Business/ Research understanding: Define business objective to undertaking analysis project. Business objective could be increasing the product sale by targeting specific group of customers, reducing the customer churn or forecasting the raw material prices. Based on business objective, a data mining problem can be defined.
- .Data understanding: The phase involves collecting the data, performing exploratory data analysis to generate initial insights, and evaluating the quality of data.
- Data preperation: The initial raw data may be dirty and requires extensive data processing. This labor-intensive phase covers all the steps of preparing the final data set, which shall be used for subsequent phases. The phase also involves selecting the variables that are appropriate for the analysis.
- Modeling: Select and apply appropriate modeling technique. This also involves model parameter turning to improve the model accuracy. Typically, several different techniques may be applied for the same mining problem. This phase also requires looping back to data preparation phase, since each model demands a data to be feed into specific format.
- Evaluation phase: Once the models are ready in the previous phase, these models must be evaluated for quality and effectiveness. Check whether the model achieves the business objective set in phase-1. For e.g. is customer segmentation derived by a model help increase product sale?
- Deployment phase: Model needs to be deployed in organisation to realise its benefits. A simple deployment could be a report, or the more complex one could be integrating the model outcome into company s’ existing MIS system.
Summary
KDD and CRISP-DM provides systematic framework that can be adapted to various business domains and data mining techniques. Both these frameworks are not completely distinct from each other. They do share few similarities in their processes (such as data cleaning, model validation phase). If you are working on a data science project, consider following KDD or CRISP-DM method to ensure well-structured and successful process.